Hey there,
On our continuing journey for adding OpenModelica support to Scilab/Xcos, now it’s time to start loading of the exported model configuration, in order to build Xcos editor interfacing functions (more on that in the near future).
As said (more or less) on previous posts, FMI2-compliant applications export code and data for dynamic systems in packages called FMUs (Functional Mock-up Units). Simply put, FMUs are Zip files containing all components necessary for simulating the given model in a host application.
- Structure of zip file of an FMU:
modelDescription.xml // Description of FMU (required file)
model.png // Optional image file of FMU icon
documentation // Optional directory containing the FMU documentation
index.html // Entry point of the documentation
<other documentation files>
sources // Optional directory containing all C sources
// all needed C sources and C header files to compile and link the FMU
// with exception of: fmi2TypesPlatform.h , fmi2FunctionTypes.h and fmi2Functions.h
// The files to be compiled (but not the files included from these files)
// have to be reported in the xml-file under the structure
// <ModelExchange><SourceFiles> ... and <CoSimulation><SourceFiles>
binaries // Optional directory containing the binaries
win32 // Optional binaries for 32-bit Windows
<modelIdentifier>.dll // DLL of the FMI implementation
// (build with option "MT" to include run-time environment)
<other DLLs> // The DLL can include other DLLs
// Optional object Libraries for a particular compiler
VisualStudio8 // Binaries for 32-bit Windows generated with
<modelIdentifier>.lib // Microsoft Visual Studio 8 (2005)
// Binary libraries
gcc3.1 // Binaries for gcc 3.1.
...
win64 // Optional binaries for 64-bit Windows
...
linux32 // Optional binaries for 32-bit Linux
<modelIdentifier>.so // Shared library of the FMI implementation
...
linux64 // Optional binaries for 64-bit Linux
...
resources // Optional resources needed by the FMU
// data in FMU specific files which will be read during initialization;
// also more folders can be added under resources (tool/model specific).
// In order for the FMU to access these resource files, the resource directory
// must be available in unzipped form and the absolute path to this directory
// must be reported via argument "fmuResourceLocation" via fmi2Instantiate.As seen above, those components are mainly the model libraries (exporting FMI2 interface functions) for the host platform, their correspondent C sources, and the model description file, which we are addressing today.
FMI2 Model Description Schema
As stated in FMI2 documentation, “All static information related to an FMU is stored in the text file modelDescription.xml in XML format”, probably to keep model libraries, processing dynamic data, as small as possible.
Whatever the reason, it’s from this description file that the simulator application should obtain information regarding model’s attributes like name, type, FMI version compatibility, and variables (whether state, input or output) number, units, names, initial values, etc…
For instance, see the case of Xcos “chaos” Modelica example block:
class chaos
input Real eps,gamma;
Real x(start=0), y(start=1);
equation
der(x)=y;
der(y)=x-x^3-eps*y+gamma*cos(time);
end chaos;
(Corresponding Modelica code)
… and resulting description file (simplified for readability):
<?xml version="1.0" encoding="UTF-8"?>
<fmiModelDescription
fmiVersion="2.0"
modelName="chaos"
guid="{61c16f51-62f0-45c8-897b-b33c354e525d}"
description=""
generationTool="OpenModelica Compiler OMCompiler v1.12.0-dev.447+g73555c0ac"
generationDateAndTime="2017-07-07T14:47:23Z"
variableNamingConvention="structured"
numberOfEventIndicators="0">
<ModelExchange
modelIdentifier="chaos">
</ModelExchange>
<ModelVariables>
<!-- Index of variable = "1" -->
<ScalarVariable
name="x"
valueReference="0"
variability="continuous"
causality="local"
initial="exact">
<Real start="0.0"/>
</ScalarVariable>
<!-- Index of variable = "2" -->
<ScalarVariable
name="y"
valueReference="1"
variability="continuous"
causality="local"
initial="exact">
<Real start="1.0"/>
</ScalarVariable>
<!-- Index of variable = "3" -->
<ScalarVariable
name="der(x)"
valueReference="2"
variability="continuous"
causality="local"
initial="calculated">
<Real derivative="1"/>
</ScalarVariable>
<!-- Index of variable = "4" -->
<ScalarVariable
name="der(y)"
valueReference="3"
variability="continuous"
causality="local"
initial="calculated">
<Real derivative="2"/>
</ScalarVariable>
<!-- Index of variable = "5" -->
<ScalarVariable
name="_D_cse1"
valueReference="4"
variability="continuous"
causality="local"
initial="calculated">
<Real/>
</ScalarVariable>
<!-- Index of variable = "6" -->
<ScalarVariable
name="eps"
valueReference="5"
variability="continuous"
causality="input"
>
<Real start="0.0"/>
</ScalarVariable>
<!-- Index of variable = "7" -->
<ScalarVariable
name="gamma"
valueReference="6"
variability="continuous"
causality="input"
>
<Real start="0.0"/>
</ScalarVariable>
</ModelVariables>
<ModelStructure>
<Derivatives>
<Unknown index="3" dependencies="2" dependenciesKind="dependent" />
<Unknown index="4" dependencies="1 2 6 7" dependenciesKind="dependent dependent dependent dependent" />
</Derivatives>
</ModelStructure>
</fmiModelDescription>from which we are most interested in obtaining:
- Model’s name/identifier for model library loading during compilation/linkage;
- Model’s GUID for validation during it’s initialization;
- Number of model’s event indicators (internal zero-crossings);
- Internal state and external variables information, which could be identified either by name (provided that variableNamingConvention is set to “structured”, which guarantees a naming convention) or properties;
- Dependency relationship between these said variables, which could allow the construction of optimized sparse Jacobian matrices for complex models.
Scilab’s Way
For Scilab, processing of that information is performed by scripts written in its own interpreted language. Thankfully (and expectedly), Scilab language already has available support for parsing XML files/strings, facilitating our work here by a large amount.
As an practical example, the code below shows how to perform this data extraction:
modelDescriptionTree = xmlRead( 'modelDescription.xml' ); // Read XML file data into a tree-like native data structure
modelDescription = modelDescriptionTree.root; // Take data tree's base node (root)
modelName = modelDescription.attributes( 'modelName' ); // Aquire and display model's name attribute
disp( strcat( [ "Model name: ", modelName ] ) );
modelGUID = modelDescription.attributes( 'guid' ); // Aquire and display model's GUID
disp( strcat( [ "Model GUID: ", modelGUID ] ) );
// Aquire and display number of model's event indicators
modelEventIndicatorsNumber = modelDescription.attributes( 'numberOfEventIndicators' );
disp( strcat( [ "Number of zero-crossings: ", modelEventIndicatorsNumber ] ) );
// Find model variables sub-node
for i=1:length( modelDescription.children )
childNode = modelDescription.children( i );
if childNode.name == 'ModelVariables' then
modelVariables = childNode;
end
end
inputNames = [];
stateNames = [];
stateDerivativeNames = [];
parameterNames = [];
outputNames = [];
variableNames = [];
// Walk through every variable node and fill the different lists according to the properties of each one
for i=1:length( modelVariables.children )
variableNode = modelVariables.children( i );
variableAttributes = variableNode.attributes;
variableName = variableAttributes( 'name' );
// Only continuous states, inputs and outputs considered
if variableAttributes( 'variability' ) == 'continuous' then
// States are internal (local or non-interfacing variables)
if variableAttributes( 'causality' ) == 'local' then
// States are defined exactly at the beginning of simulation
if variableAttributes( 'initial' ) == 'exact' then
stateNames( $ + 1 ) = variableName;
// State derivatives are calculated dynamically from current states
elseif variableAttributes( 'initial' ) == 'calculated' then
// Model descriptions could also present internal calculated
// variables which are not state derivatives
if variableNode.children( 1 ).attributes( 'derivative' ) <> [] then
stateDerivativeNames( $ + 1 ) = variableName;
end
end
// Input and output interfacing values
elseif variableAttributes( 'causality' ) == 'input' then
inputNames( $ + 1 ) = variableName;
elseif variableAttributes( 'causality' ) == 'output' then
outputNames( $ + 1 ) = variableName;
end
// Parameters are adjustable (in editor) values that remain the sames during the rest of simulation
elseif variableAttributes( 'variability' ) == 'fixed' then
if variableAttributes( 'causality' ) == 'parameter' then
parameterNames( $ + 1 ) = variableName;
end
end
variableNames( $ + 1 ) = variableName;
end
// Display results
disp( inputNames );
disp( stateNames );
disp( stateDerivativeNames );
disp( parameterNames );
disp( outputNames );
// Fill state derivatives dependency matrix (initialized with "False" booleans)
aux = ones( size( stateDerivativeNames, 1 ), size( stateNames, 1 ) );
dependencyMatrix=( aux <> aux );
// Find model structure -> derivatives sub-node
modelDerivativesStructure = [];
for i=1:length( modelDescription.children )
childNode = modelDescription.children( i );
if childNode.name == "ModelStructure" then
modelStructure = childNode;
for i=1:length( modelStructure.children )
childNode = modelStructure.children( i );
if childNode.name == "Derivatives" then
modelDerivativesStructure = childNode;
end
end
end
end
// Mark (set to "True") every state variable on which each derivative depends
if modelDerivativesStructure <> [] then
for i=1:length( modelDerivativesStructure.children )
derivativeAttributes = modelDerivativesStructure.children( i ).attributes;
// Global index of derivative variable
variableIndex = round( strtod( derivativeAttributes( "index" ) ) );
derivativeName = variableNames( variableIndex );
// Index of derivative variable in derivatives list
derivativeIndex = find( stateDerivativeNames == derivativeName );
if derivativeIndex <> [] then
// Transform string of derivative dependencies in a list of indexes
dependencyIndexes = round( strtod( strsplit( derivativeAttributes("dependencies"), " " ) ) );
for j=1:size( stateNames, 1 )
stateName = stateNames( j );
// Take global index of state variable and verify if it is a dependency
variableIndex = find( variableNames == stateName );
if find( dependencyIndexes == variableIndex ) <> [] then
dependencyMatrix( derivativeIndex, j ) = %t;
else
dependencyMatrix( derivativeIndex, j ) = %f;
end
end
end
end
end
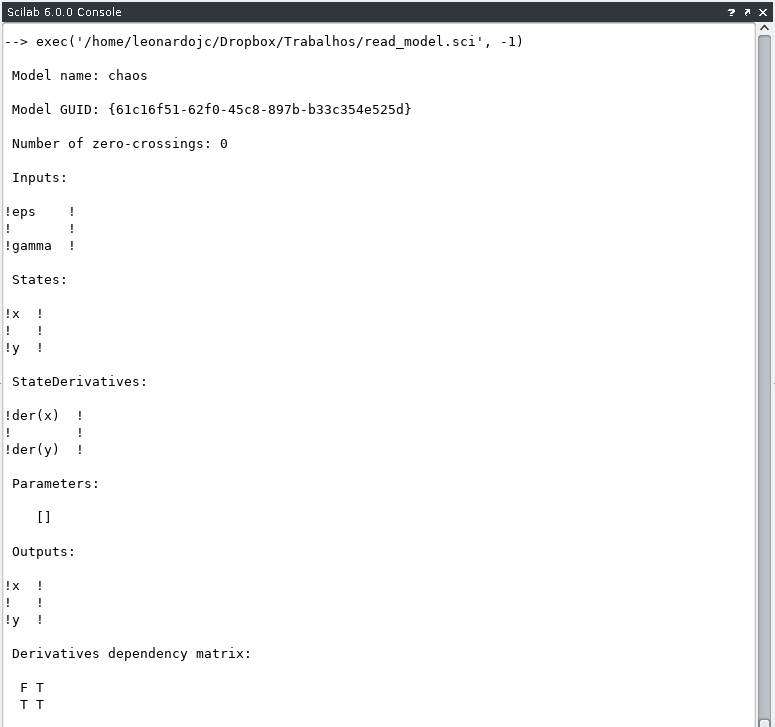
disp( dependencyMatrix, "Derivatives dependency matrix:" );… whose output can be seen in Scilab’s console:
Wrapping Up
The last piece of code was intended just for showing how the XML information could be read in Scilab scripts, but almost the same commands can compose the code responsible for filling the correspondent Xcos block data structure. That will be addressed in our next post.
Thanks one more time for sticking by. See you soon !