Wassup, dudines and dudes ?
I heard a lot about how the last 10% of a project’s deliverables take more time and effort than the previous 90%, and I am, once again, noticing this. Not that I’m saying we currently have a 90% complete Scilab kernel (actually, I don’t really know), but the idea still applies.
After writing code to handle the Jupyter communication infrastructure, threading, Scilab integration, building and [limited] processing of the most complex messages, we end up still having to handle simpler message types, that request and reply tiny bits® of information essential for a correct backend behavior.
Taking Jupyter messaging documentation as reference (as always, btw), we try to write proper handlers for the listed messages:
Introspection
Introspection requests can be used by a client to get detailed information about a variable/object. They are issued when an appropriate frontend receives a page payload, that are e.g. returned from the IPython kernel on the execute _reply for commands like “var_name?” or “var_name??” (Payloads aren’t implemented on the Scilab kernel yet).
- inspect_request message specification
content = {
# The code context in which introspection is requested
# this may be up to an entire multiline cell.
'code' : str,
# The cursor position within 'code' (in unicode characters) where inspection is requested
'cursor_pos' : int,
# The level of detail desired. In IPython, the default (0) is equivalent to typing
# 'x?' at the prompt, 1 is equivalent to 'x??'.
# The difference is up to kernels, but in IPython level 1 includes the source code
# if available.
'detail_level' : 0 or 1,
}- inspect_reply message specification
content = {
# 'ok' if the request succeeded or 'error', with error information as in all other replies.
'status' : 'ok',
# found should be true if an object was found, false otherwise
'found' : bool,
# data can be empty if nothing is found
'data' : dict,
'metadata' : dict,
}- Our inspect_{request,reply} message handler, from JupyterKernel class
#include "symbol.hxx" // Variable symbol (identifier) class
#include "context.hxx" // Context (state holding variables) class
#include "internal.hxx" // Internal generic Scilab type class
void JupyterKernel::HandleInspectionRequest( Json::Value& commandContent, Json::Value& replyContent )
{
std::string code = commandContent.get( "code", "" ).asString();
int cursorPosition = commandContent.get( "cursor_pos", 0 ).asInt();
// Not differentiating between levels of detail so far
int detailLevel = commandContent.get( "detail_level", 0 ).asInt();
// Consider the searched variable name/symbol the word
// (between spaces) over which the cursor is located
size_t variableNameStartPosition = code.substr( 0, cursorPosition ).find_last_of( " \n\r\t" );
if( variableNameStartPosition == std::string::npos ) variableNameStartPosition = 0;
else variableNameStartPosition += 1;
size_t variableNameEndPosition = code.substr( cursorPosition ).find_first_of( " \n\r\t" );
std::string variableName = code.substr( variableNameStartPosition, variableNameEndPosition );
// A symbol is defined by a wide string (more than 8 bits per character)
// So we perform a format conversion
symbol::Symbol variableSymbol( std::wstring( variableName.begin(), variableName.end() ) );
// Scilab's context object is a single instance (singleton) shared accross the entire aplication
types::InternalType* variableType = symbol::Context::getInstance()->get( variableSymbol );
replyContent[ "status" ] = "ok";
replyContent[ "found" ] = false;
replyContent[ "data" ] = Json::Value( Json::objectValue );
replyContent[ "metadata" ] = Json::Value( Json::objectValue );
if( variableType != NULL )
{
replyContent[ "found" ] = true;
// For now, we only acquire the variable type string identifier
std::wstring typeWString = variableType->getTypeStr();
replyContent[ "data" ][ "Type" ] = std::string( typeWString.begin(), typeWString.end() );
}
}Completion
On many interactive shells, the Tab key is a shortcut for displaying the autocompletion options for the current variable or command being entered. Jupyter defines a type of message for offloading this completion resolution to the kernel.
- complete_request message specification
content = {
# The code context in which completion is requested
# this may be up to an entire multiline cell, such as
# 'foo = a.isal'
'code' : str,
# The cursor position within 'code' (in unicode characters) where completion is requested
'cursor_pos' : int,
}- complete_reply message specification
content = {
# The list of all matches to the completion request, such as
# ['a.isalnum', 'a.isalpha'] for the above example.
'matches' : list,
# The range of text that should be replaced by the above matches when a completion is accepted.
# typically cursor_end is the same as cursor_pos in the request.
'cursor_start' : int,
'cursor_end' : int,
# Information that frontend plugins might use for extra display information about completions.
'metadata' : dict,
# status should be 'ok' unless an exception was raised during the request,
# in which case it should be 'error', along with the usual error message content
# in other messages.
'status' : 'ok'
}- Our complete_{request,reply} message handler, from JupyterKernel class
extern "C" {
#include "completion.h" // Scilab's completion has only a C interface
}
void JupyterKernel::HandleCompletionRequest( Json::Value& commandContent, Json::Value& replyContent )
{
std::string code = commandContent.get( "code", "" ).asString();
int cursorPosition = commandContent.get( "cursor_pos", 0 ).asInt();
// Consider the searched token only the substring of the code after
// the last space character and before the cursor position
code.resize( cursorPosition, ' ' );
size_t tokenStartPosition = code.find_last_of( " \n\r\t" );
if( tokenStartPosition == std::string::npos ) tokenStartPosition = 0;
else tokenStartPosition += 1;
std::string token = code.substr( tokenStartPosition );
int completionMatchesCount = 0;
// Scilab internal call that returns the list of matching strings (char pointers)
char** completionMatches = completion( (const char*) token.data(), &completionMatchesCount );
// Create and fill the returning dictionary
replyContent[ "matches" ] = Json::Value( Json::arrayValue );
for( int matchIndex = 0; matchIndex < completionMatchesCount; matchIndex++ )
replyContent[ "matches" ][ matchIndex ] = std::string( completionMatches[ matchIndex ] );
replyContent[ "cursor_start" ] = (int) tokenStartPosition;
replyContent[ "cursor_end" ] = cursorPosition;
replyContent[ "metadata" ] = Json::Value( Json::objectValue );
replyContent[ "status" ] = "ok";
}The result can be seen by clicking Tab after a partial command name on QtConsole:
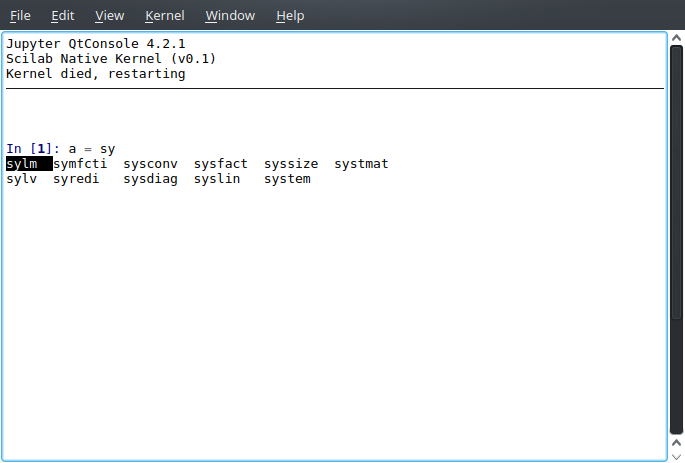
(The kernel dying [heartbeat thread doesn't respond in time, I guess] is a bug to be solved)
Completeness
On some Jupyter frontends, you can force the submission of a command for execution with Shift+Enter, but it’s more convenient when it send complete commands automatically (when typing just Enter), waiting for more input when a multiline one (like for loops or if/else blocks) is being entered. For querying this information from the running kernel, Jupyter defines a specific message format.
- is_complete_request message specification
content = {
# The code entered so far as a multiline string
'code' : str,
}- is_complete_reply message specification
content = {
# One of 'complete', 'incomplete', 'invalid', 'unknown'
'status' : str,
# If status is 'incomplete', indent should contain the characters to use
# to indent the next line. This is only a hint: frontends may ignore it
# and use their own autoindentation rules. For other statuses, this
# field does not exist.
'indent': str,
}- Our is_complete_{request,reply} message handler, from JupyterKernel class
#include "parser.hxx"
void JupyterKernel::HandleCompletenessRequest(Json::Value& commandContent, Json::Value& replyContent)
{
// Independent parser (not the engine's one)
// "static" so that previous state is kept
static Parser checker;
std::string code = commandContent.get( "code", "" ).asString();
checker.parse( code.data() ); // Verify code without submitting it to the engine
bool isComplete = false;
replyContent[ "status" ] = "incomplete"; // when "unknown" ?
if( checker.getControlStatus() == Parser::ControlStatus::AllControlClosed )
{
// An invalid command also exits control blocks
isComplete = true;
if( checker.getExitStatus() == Parser::ParserStatus::Succeded ) // typo
replyContent[ "status" ] = "complete";
else
{
replyContent[ "status" ] = "invalid";
checker.cleanup();
}
}
// Frontends like QtConsole use their own prompt string and appends
// the received one to the code, so this should be empty
if( not isComplete ) replyContent[ "indent" ] = "";
}Again, testing on a QtConsole, we compare the results for complete and incomplete commands.
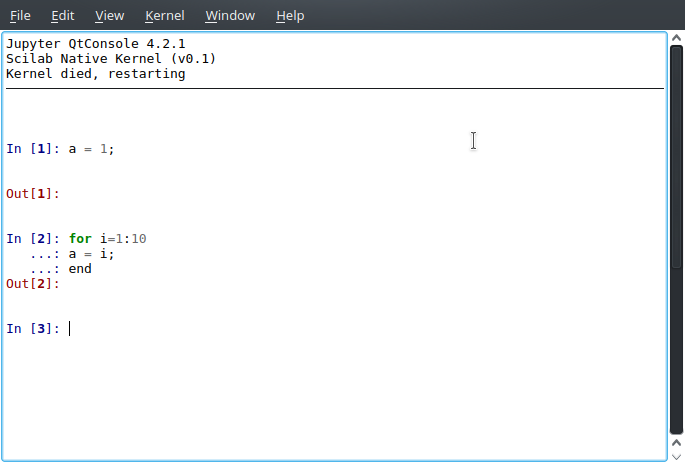
As we are approaching the week of GSoC Final Term Evaluation, I’ll probably have time for just one more update (inside GSoC’s time frame, I mean, as I pretend to keep working on it), where I wish to show a server input request implementation working.
Thanks for reading. See you next time !!